How to deploy Apache Cassandra on Kubernetes with AxonOps management tool. AxonOps provides the GUI management for the Cassandra cluster.

There was a requirement by this customer to retrieve some data that was already purged due to TTL.
The post An Interesting Behaviour Observed with Cassandra Concurrent Compaction appeared first on digitalis.io.
]]>One of our customers have a short TTL for an IoT use case. The data model is a standard Cassandra time series with a sensor ID as the partition key and timestamp as the clustering column. The following CQL schema is used for this.
CREATE TABLE sensors.sensordata (
sensor_id text,
sensor_time timestamp,
sensor_value int,
PRIMARY KEY (sensor_id , sensor_time )
) WITH CLUSTERING ORDER BY (sensor_time DESC)
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32',
'min_threshold': '8'};There was a requirement by this customer to retrieve some data from the above table that was already purged due to TTL. In order to facilitate this request we had restored SSTable files from the production cluster backups to a separate cluster, stripping out the TTLs before loading them using the sstableloader command.
We had provisioned a cluster in AWS using EC2 i3.8xlarge instances with local NVMe volumes allocated for Cassandra data. 4 1.7TB NVMe volumes were combined into a single volume using LVM2. Apache Cassandra version 3.11.5 was used for this restoration process.
Since there were 10’s of thousands of SSTables the temporary Cassandra cluster was tasked with compaction of the newly loaded SSTables before we could query the data for specific partitions. The recommendation for concurrent_compactors is to set it to the number of CPU cores. In this case we used the value of 16, and compaction_throughput_mb_per_sec set to 0, with a view to complete the compaction as quickly as possible leveraging the CPU cores and high throughput disk bandwidth from local NVMe volumes.
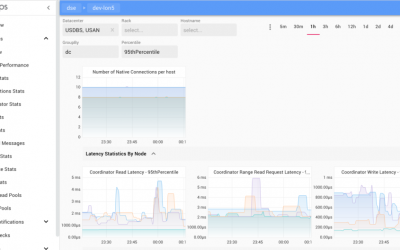
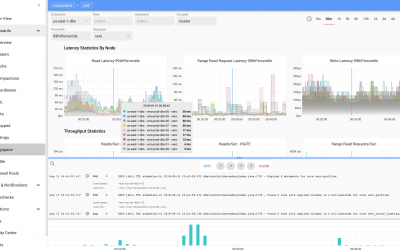
Using nodetool compcationstats command we observed the number of concurrent compaction processes ramp up slowly. However, it was interesting to note that the overall compaction throughput decreased as the concurrency increased. The charts below show the system disk throughput captured during the initial compaction process. We then decreased the concurrent compactors using nodetool setconcurrentcompactors command to 4. As the number of concurrency decreased the overall compaction throughput increased again.
It is worth mentioning that there were no queries running in this cluster during this period.

The CPU utilisation ramped up as the concurrency increased, and reduced as the concurrency decreased.

IOWait remained relatively low during this period.

The charts below shows some compaction threadpool statistics.

We observed that Cassandra is unable to leverage all the available CPU cores and disk IO for compaction with by increasing the number of concurrent compactors. The optimum value for concurrent compactors appears to be below 5 in order to maintain the highest throughput offered by the available disk bandwidth.
It is important to note that this observation was only for a single table. You may still gain benefits from increasing the concurrent compactors to the number of CPU cores if you have multiple tables in your schema.

The post An Interesting Behaviour Observed with Cassandra Concurrent Compaction appeared first on digitalis.io.
]]>The post AxonOps Beta Released appeared first on digitalis.io.
]]>
Frustrated by the operational tooling available for Apache Cassandra, Digitalis built their own called AxonOps. AxonOps provides the following assistance for your Cassandra clusters.

It’s been a while since my last blog about AxonOps but we’re excited to announce that AxonOps beta is now available for you to download and install! The installation instructions are available from https://docs.axonops.com
AxonOps is an operational tool for your Apache Cassandra clusters – regardless of where they are deployed – cloud or on-premises. Please read my previous blog to for more detailed motivations and descriptions.
It has the following functionalities;
AxonOps does all of this with a very simple deployment model;


We have made this as simple as possible with our APT and YUM repositories and simple steps for installation. See https://docs.axonops.com/installation/axon-server/ubuntu/, https://docs.axonops.com/installation/axon-server/centos/
We are looking for some beta testers as we’d love to hear your feedback on AxonOps. We believe the implementation process is immensely quicker and easier than cobbling together multiple standard tools like Grafana, Prometheus, ELK, Nagios, etc, as AxonOps works out of the box with negligible amount of configurations to get going. All the charts and dashboards are laid out intuitively for managing Cassandra.
Please contact us at [email protected] if you are interested to learn more about the product.
Co-founder & CEO
Hayato is an experienced technology leader, architect, software engineer, DevOps practitioner, and a real-time distributed data expert. He is passionate about building highly scalable internet facing systems. He came across Apache Cassandra in 2010 and became an advocate for this open-source distributed database technology.
How to deploy Apache Cassandra on Kubernetes with AxonOps management tool. AxonOps provides the GUI management for the Cassandra cluster.
We are excited to announce that AxonOps beta is now available for you to download and install!
AxonOps is a platform we have created which consists of 4 key components – javaagent, native agent, server, and GUI making it extremely simple to deploy in any Linux infrastructure
The post AxonOps Beta Released appeared first on digitalis.io.
]]>The post AxonOps appeared first on digitalis.io.
]]>
Digitalis was founded just over 2.5 years ago, to provide expertise in complex distributed data platforms. We provide both consulting services and managed services for Cassandra, Kafka, Spark, Elasticsearch, DataStax Enterprise, Confluent and more.
In the beginning we started using a number of popular open source tools to implement our monitoring and alerting for our managed services, namely Prometheus, Grafana, ELK, Consul, Ansible etc. These are fantastic open source tools and they have served us well, giving us the confidence to manage enterprise deployment of distributed data platforms – alerting us when there are problems, ability to diagnose issues quickly, automatically performing routine scheduled tasks etc.
We found over time that these tools have become the focal point instead of the products we are supposed to be looking after. Each one of these open source tools requires frequent updates, configuration changes etc. imposing a significant amount of management effort to keep on top of it all. The complexity of the tools deployment architecture made the stack slow to deploy for our customers, in particular highly regulated industries such as financial services and healthcare.
We went back to the drawing board with the aim of reducing the efforts needed to on-board new customers and made a wish list.
What the tool is not:
The target deployment architecture needed to be as simple as possible.
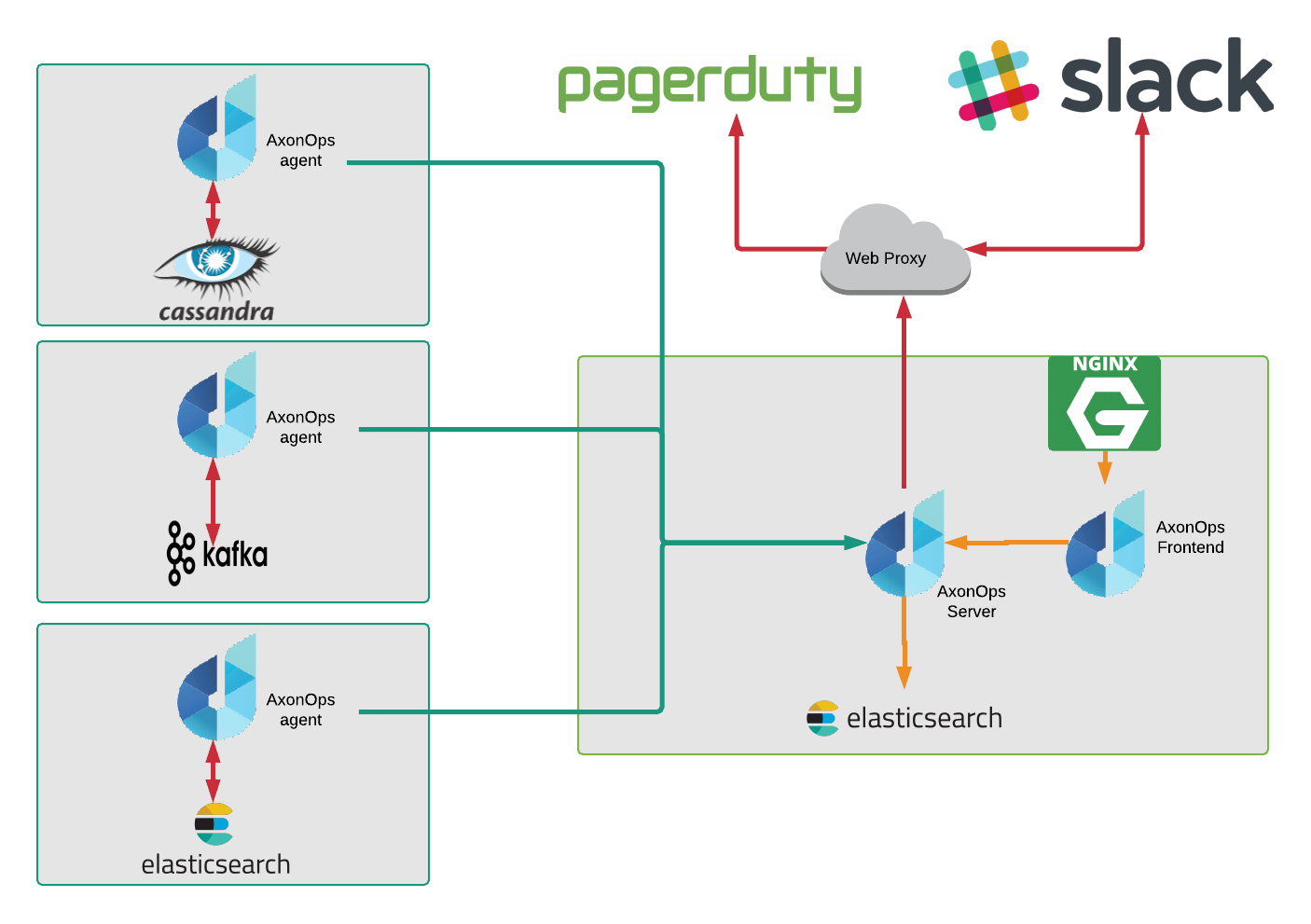
We imagineered, built the tool, and called it AxonOps. It consists of just 4 components – javaagent, native agent, server, and GUI making this extremely simple to deploy in any infrastructure as long as it is Linux!
We imagineered, built the tool, and called it AxonOps. It consists of just 4 components – javaagent, native agent, server, and GUI making this extremely simple to deploy in any infrastructure as long as it is Linux!
AxonOps agent makes a single socket connection to the server for transporting the following;
Agent-server connectivity works securely over the web infrastructure. To prove it we have successfully tested this working over the internet, load balancers before reaching the backend AxonOps server.
We have put in a mammoth effort in designing the agent as efficient as possible. We carefully defined and crafted a network protocol to keep the bandwidth requirements very low, even when shipping over 20,000 metrics every 5 seconds. This was unthinkable with our previous setup with jmx_exporter and Prometheus which required us to throw away most of the metrics. Now we have all the metrics at hand at a much higher resolution.
We avoided using JMX when connecting to the JVM, as many of you will be aware that scraping a large number of metrics causes CPU spikes. Instead, we built a Java agent that pushes all metrics to the native Linux AxonOps agent running on the same server. The Java agent also captures various internal events including authentication, JMX events (when people execute nodetool commands), DDL, DCL, etc. which are then shipped to the server, monitored and stored in Elasticsearch for queries.
We built our server in Golang. Having spent many years building JVM based applications in the past, we are extremely impressed and pleased with the double digit megabytes memory footprint!
AxonOps server provides the endpoint for agents to connect into, as well as the API for the GUI.
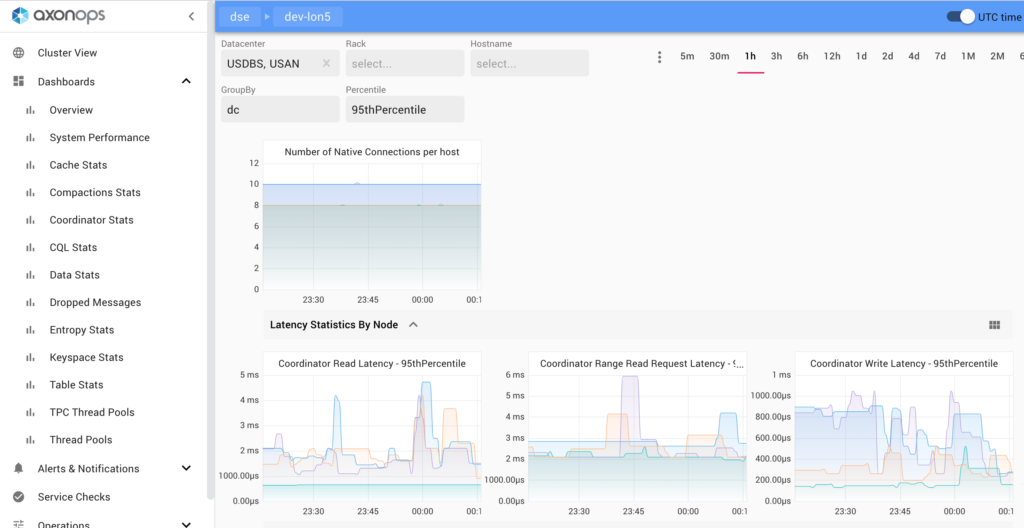
The metrics API we implemented is Prometheus compatible. Our dashboard provides a comprehensive set of charts, but your existing Grafana can also be connected to AxonOps server to integrate with other dashboards.
AxonOps currently persists all its configurations, metrics, logs, and events into Elasticsearch. We need Elasticsearch for the storage of events and logs to make them searchable. For this initial version we decided to use Elasticsearch for all of AxonOps persistence requirements for simplicity. However, we are acutely aware of more efficient time series databases available on the market, and it is on our roadmap to add support for these.
The GUI is built as a single executable Linux binary file containing all assets, using Node.js and React.js frameworks. We decided to use Material Design look and feel, with an aim to make the GUI snappy and intuitive to use.
Some of the functionalities we have implemented are described below.
We took inspiration from Grafana and ELK when designing our dashboards, but embedded both charts and logs in a single view with time range governing the display of both features. Alert rules can be defined graphically in each chart to integrate with PagerDuty and Slack for alerts etc.
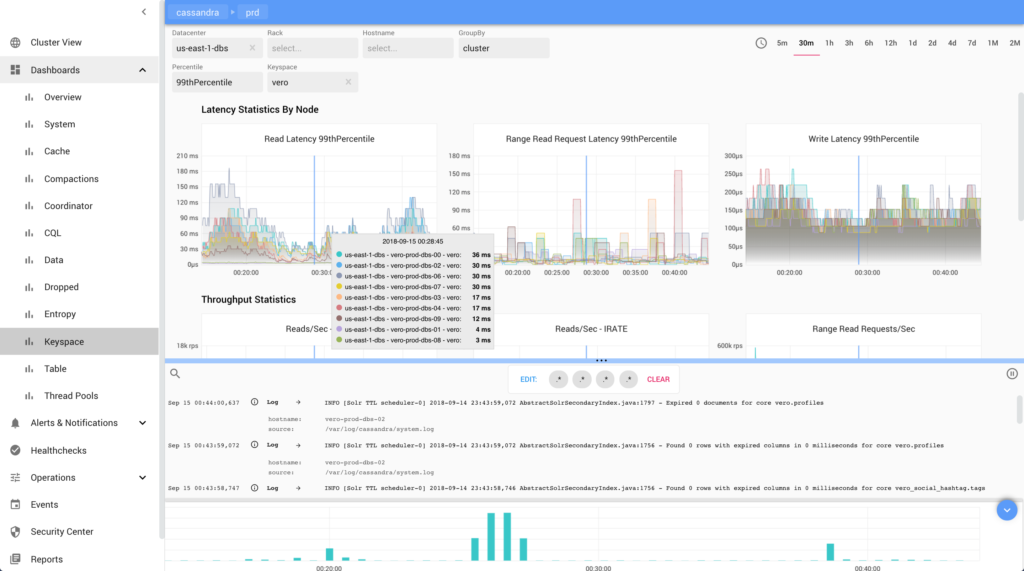
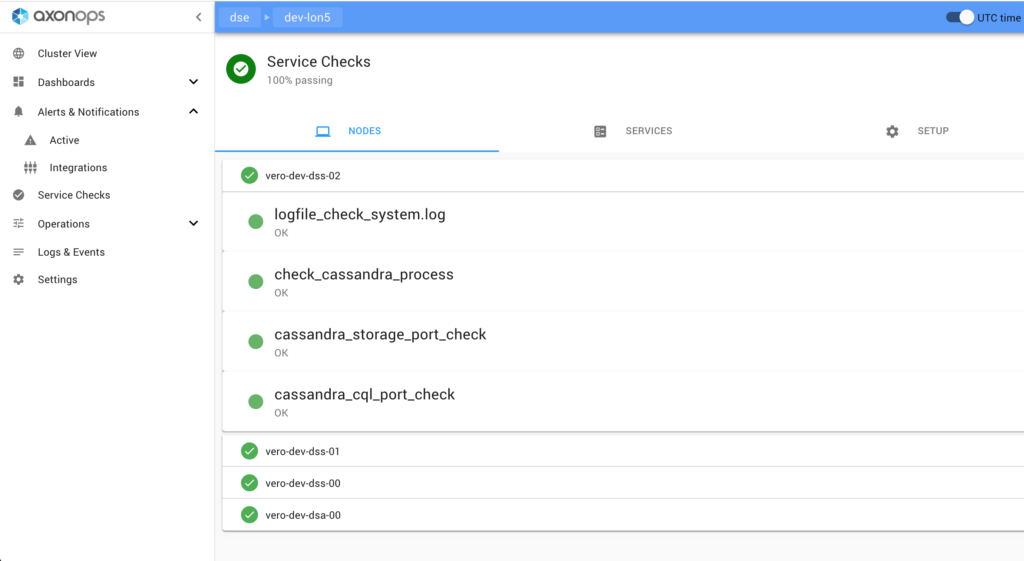
Having a service health dashboard to give us quick RAG status is extremely important to us. Systems like Nagios and Consul provided such functionality prior to building AxonOps. Again we wanted this integrated in the solution.
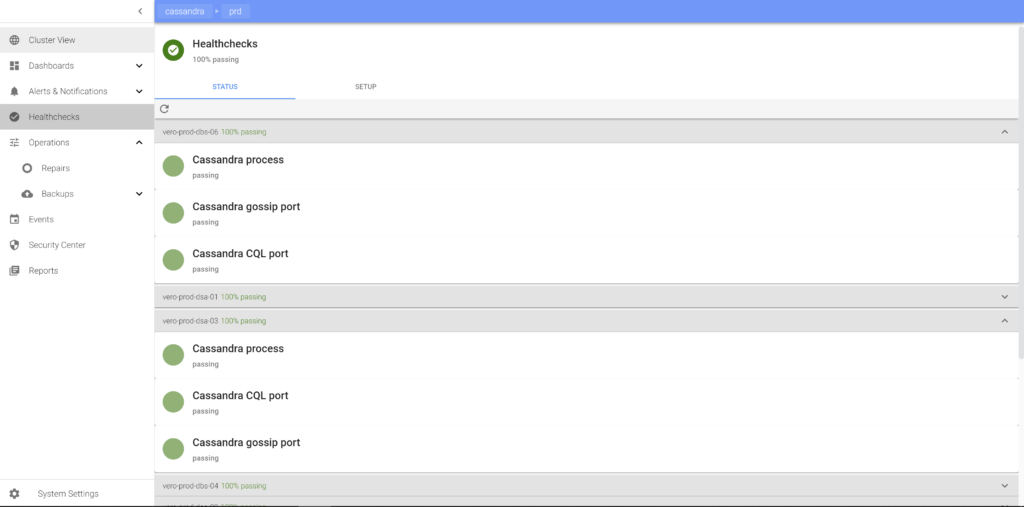
We have built this in a way that the configurations can be dynamically updated and pushed out to the agents. This means we do not have to deploy any scripts to the individual target servers. There are three types of checks we have implemented which cover all of our use cases;
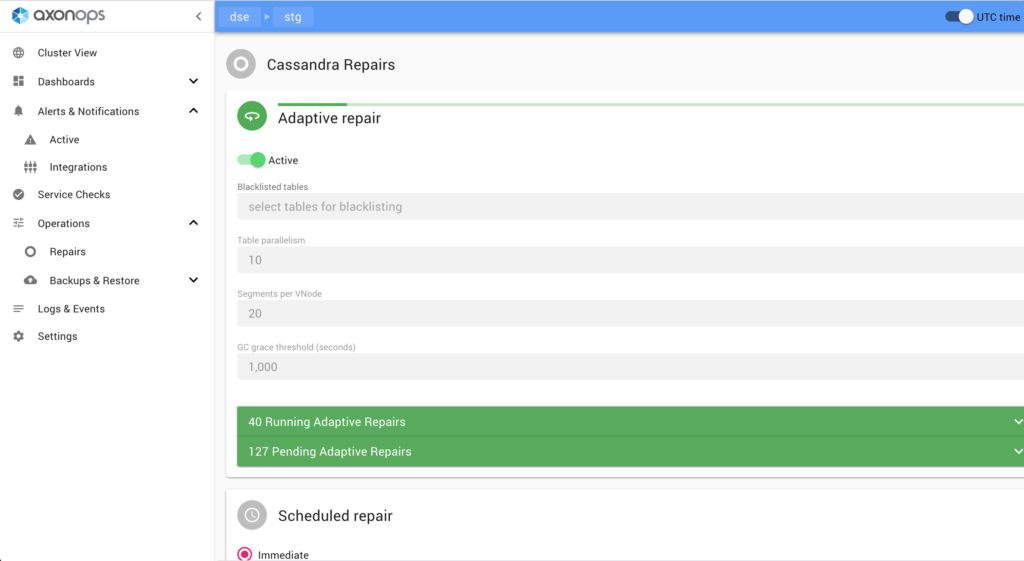
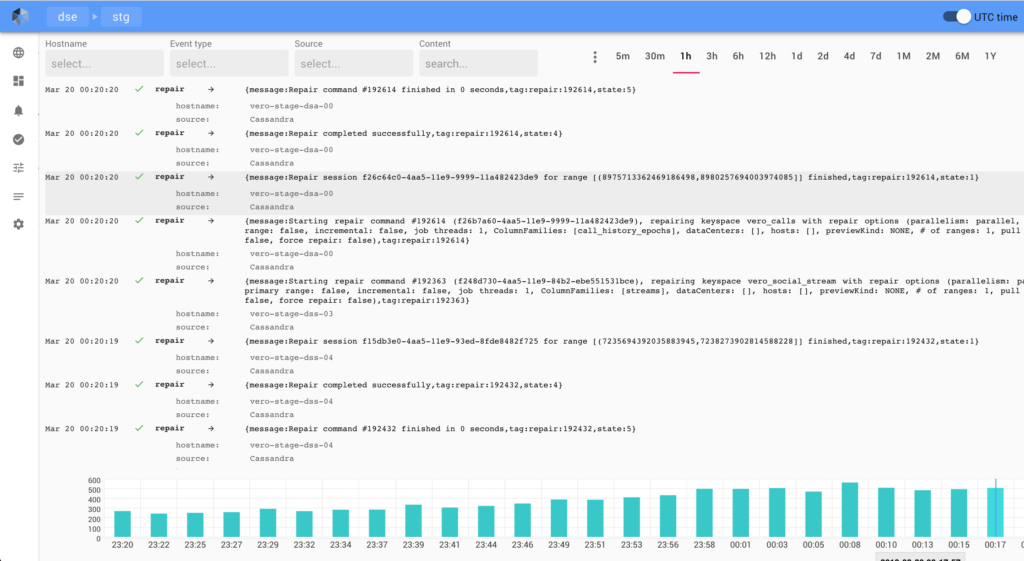
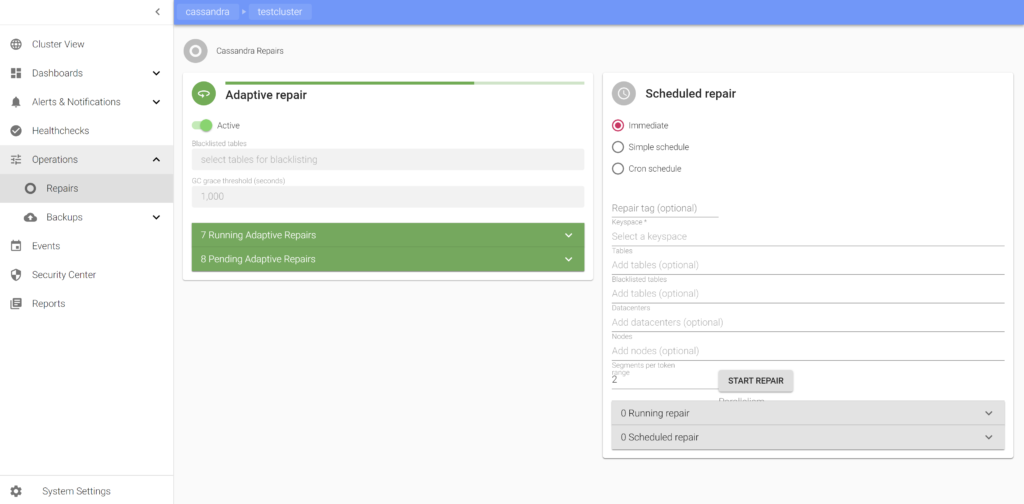
Repair is one of the most difficult aspects of managing Cassandra clusters. There are only few tools available out there, most popular one being Reaper. I was once told by an engineer at Spotify the name was derived from mispronouncing the word “repair” with Swedish accent! Anyway, we did go through the Reaper code to see if this may work for us. Upon analysis we decided to implement our own.
Since AxonOps collects performance metrics and logs, we theorised a slightly more sophisticated approach than Reaper – an “Adaptive” repair system which regulates the velocity (parallelism and pauses between each subrange repair) based on performance trending data. The regulation of repair velocity takes input from various metrics including CPU utilisation, query latencies, Cassandra thread pools pending statistics, and IOwait percentage, while tracking the schedule of repair based on gc_grace_seconds for each table.
The idea of this is to achieve the following:
In essence, adaptive repair regulator slows down the repair velocity when it deems the load is going to be high based on the gradient of the rate of increase of load, and speeds up to catch up with the repair schedule when the resources are more readily available.
There is another reason why we decided to not go with Reaper. Reaper requires JMX access from the server, which does not fit well with AxonOps single socket connection model. The adaptive repair service running on AxonOps server orchestrates and issues commands to the agents over this existing connection.
From a user’s point of view, there is only a single switch to enable this service. Keep this enabled and AxonOps will take care of the repair of all tables for you. We are also looking into implementing adaptive compaction control using a similar logic to the adaptive repair.
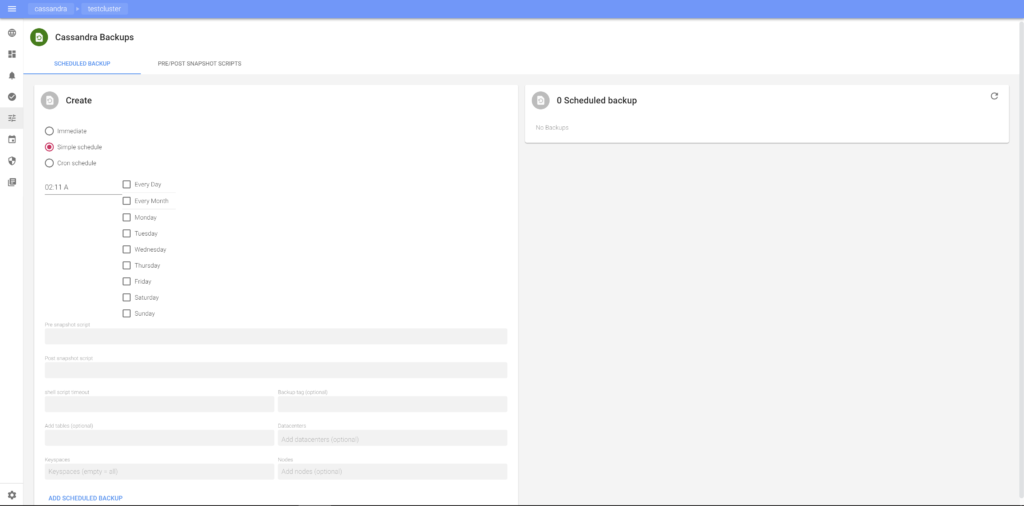
Scheduled backup & restore is another requirement for our customers. We have added this feature in a way that it can flexibly integrate with various backup solutions that our customers use. It schedules Cassandra snapshots, with an option to attach pre/post snapshot script execution for each schedule. These scripts are defined on the AxonOps server-side, pushed down dynamically to the agents at execution time, removing the need to have them deployed on each target server in advance. I should point out here that the scripts are pushed down to the agent using the agent/server connection and it does not require SSH access.
We like to see our operational activities being reported into Slack. We are also heavily reliant on PagerDuty for alerting us on problems for our managed services customers. AxonOps naturally had to have the integrations built into it so event notifications or alerts can be sent to the tools we use!

We have built AxonOps for ourselves but we are excited about it and we’d like to share this with you. We are shortly going to make AxonOps available for anybody to download and use for free! Please send us an email to [email protected] if you are interested. We’re currently working on the documentation, website, and license but we’ll get in touch when we are ready for you to download.
Co-founder & CEO
Hayato is an experienced technology leader, architect, software engineer, DevOps practitioner, and a real-time distributed data expert. He is passionate about building highly scalable internet facing systems. He came across Apache Cassandra in 2010 and became an advocate for this open-source distributed database technology.
How to deploy Apache Cassandra on Kubernetes with AxonOps management tool. AxonOps provides the GUI management for the Cassandra cluster.

One of our customers have a short TTL for an IoT use case. The data model is a standard Cassandra time series with a sensor ID as the partition key and timestamp as the clustering column.
There was a requirement by this customer to retrieve some data that was already purged due to TTL.
We are excited to announce that AxonOps beta is now available for you to download and install!
The post AxonOps appeared first on digitalis.io.
]]>The post Digitalis named in top 10 Managed IT Services companies appeared first on digitalis.io.
]]>
digitalis.io has been featured by CIO Applications magazine Europe edition, as one of the top 10 Managed IT Services companies of 2018!
Click on the link below for the online edition of this magazine.
https://www.cioapplicationseurope.com/magazines/September2018/ManagedITServices/
“
We are excited to announce that AxonOps beta is now available for you to download and install!
AxonOps is a platform we have created which consists of 4 key components – javaagent, native agent, server, and GUI making it extremely simple to deploy in any Linux infrastructure

Digitalis named one of the top 10 Managed IT Services companies of 2018!
The post Digitalis named in top 10 Managed IT Services companies appeared first on digitalis.io.
]]>digitalis.io is sponsoring Cassandra Summit 2016 in San Jose! Come and talk to us if you are attending the summit.
We are excited to announce that AxonOps beta is now available for you to download and install!
AxonOps is a platform we have created which consists of 4 key components – javaagent, native agent, server, and GUI making it extremely simple to deploy in any Linux infrastructure
Digitalis named one of the top 10 Managed IT Services companies of 2018!
The post digitalis.io @ Cassandra Summit 2016 appeared first on digitalis.io.
]]>QiO (http://qio.io) – an exciting startup revolutionising the engineering industry with their innovative Nautilian platform has named digitalis.io as a partner for delivering the solution – http://qio.io/news. We are very excited to be working with QiO and to make this announcement!
We are excited to announce that AxonOps beta is now available for you to download and install!
AxonOps is a platform we have created which consists of 4 key components – javaagent, native agent, server, and GUI making it extremely simple to deploy in any Linux infrastructure
Digitalis named one of the top 10 Managed IT Services companies of 2018!
The post QiO names digitalis.io as a partner appeared first on digitalis.io.
]]>The post digitalis.io partners with Confluent.io appeared first on digitalis.io.
]]>digitalis.io today announced a formal partnership with Confluent.io! Confluent.io is the provider of world’s leading data streaming platform built on Apache Kafka, and is founded by the original authors of the software at LinkedIn. Confluent.io is enabling enterprises wanting to take advantage of the open source software by providing the software, support, consulting and training.
digitalis.io can not only help organisations adopt this technology by providing the expertise on Confluent.io platform and Apache Kafka, we can also integrate the product with other innovative real-time data solutions such as Apache Spark, Apache Cassandra and DataStax Enterprise to provide scalable high throughput ingestion systems for today’s performance needs.
By engaging digitalis.io customers will have access to some of the very best talents in the industry on designing, tuning, and administering the platform without the worry of staff retention. The services we offer include managed services, consulting, and data API development.
Our managed service for DataStax Enterprise can be hosted in the customer’s own data centres, in the Infrastructure-as-a-Service cloud provides such as Amazon Web Services, Google Compute Engine, Rackspace, Microsoft Azure, or any other providers, or hybrid across any of the above.
For more information, please contact us.
digitalis.io is a company founded by ex-DataStax Solutions Architects who, together have 40 years of experience in building complex enterprise software, platforms, processes, and automation tools. Through this knowledge and experience, digitalis.io supports development organisations and central IT functions in adopting new distributed data technologies to gain competitive advantages. The team is located in London and supports the Europe, Middle East, and Africa (EMEA) region.

If you want to understand how to easily ingest data from Kafka topics into Cassandra than this blog can show you how with the DataStax Kafka Connector.

If you want to understand what Apache NiFi is, this blog will give you an overview of its architecture, components and security features.

Do you want to know securely deploy k3s kubernetes for production? Have a read of this blog and accompanying Ansible project for you to run.
The post digitalis.io partners with Confluent.io appeared first on digitalis.io.
]]>The post digitalis.io partners with DataStax appeared first on digitalis.io.
]]>digitalis.io today announced a formal partnership with DataStax! DataStax is the provider of world’s leading data platform built on Apache Cassandra, Apache Solr, and Apache Spark, purpose-built for the performance and availability demands of web, mobile and Internet of Things (IoT) applications. Many mission critical internet facing applications are relying on DataStax Enterprise software to build disaster proof, always on data backend. In partnership with DataStax, digitalis.io provides the operational expertise in maintaining this cutting edge distributed database platform in enterprise environments across many industry verticals from financial services, media, utilities, gaming, e-commerce, telecoms, to industrial use cases.
Organisations transitioning from RDBMS to Apache Cassandra and DataStax Enterprise can obtain our expertise on;
Greenfield projects can benefit from our expertise on;
By engaging digitalis.io customers will have access to some of the very best talents in the industry on designing, tuning, and administering the platform without the worry of staff retention. The services we offer include proactive monitoring, reporting, and participation during incidents.
Our managed service for DataStax Enterprise can be hosted in the customer’s own data centres, in the Infrastructure-as-a-Service cloud provides such as Amazon Web Services, Google Compute Engine, Rackspace, Microsoft Azure, or any other providers, or hybrid across any of the above.
For more information, please contact us.
digitalis.io is a company founded by ex-DataStax Solutions Architects who, together have 40 years of experience in building complex enterprise software, platforms, processes, and automation tools. Through this knowledge and experience, digitalis.io supports development organisations and central IT functions in adopting new distributed data technologies to gain competitive advantages. The team is located in London and supports the Europe, Middle East, and Africa (EMEA) region.

The post digitalis.io partners with DataStax appeared first on digitalis.io.
]]>