


Introduction
The traditional approach to server management, SSH into a box, orchestration via Ansible or Puppet, run updates, tweak configurations, etc, is not the only way to do things.
Immutable infrastructure offers a compelling alternative: build server images once, deploy them everywhere, and never modify them in place. When changes are needed, you build a new image and replace the old servers entirely. If the virtual machine fails, replace it or let the cloud provider replace it for you because it failed the health checks.
This is in many ways what containerised platforms like Kubernetes offer, but not all applications can or should be run in containers.
The sweet spot lies in balancing immutability with practicality. Whilst you can bake everything into a machine image, the resulting images become enormous, slow to build, and inflexible. The pattern we've found most effective at Digitalis splits the responsibility: Packer creates a base image with the operating system, security hardening, and common tooling pre-installed, then cloud-init or similar initialisation systems handle the final environment-specific configuration on first boot. This approach gives you the reproducibility benefits of immutable infrastructure whilst maintaining the flexibility to adapt servers to their specific roles and environments without rebuilding images for every configuration change.
This hybrid model addresses real operational challenges we've encountered managing production infrastructure across multiple cloud providers. You gain the confidence that comes from knowing exactly what's running in production because it's literally the same image you tested in staging. You eliminate configuration drift because servers never change after deployment. And you maintain the agility to deploy environment-specific configurations without the overhead of maintaining dozens of nearly-identical machine images.
The role of HashiCorp Packer
HashiCorp Packer is an open-source tool designed to automate the creation of identical machine images for multiple platforms from a single source configuration. Rather than manually provisioning and configuring servers each time you need to deploy infrastructure, Packer allows you to define your desired system state once and build pre-configured images that are ready to boot and run across different environments.
Our usual approach is a combination of Packer with Ansible. We follow this simple approach:
- Packer creates the image to the selected cloud provider or on-premises infrastructure such as vSphere, XCP-ng, oVirt, OpenStack or even Kube-Virt!
- Packer triggers a provisioner, Ansible for us in most cases
- The provisioner configures the virtual machine up to our high standards of security (we follow the PCI-DSS benchmarks) and leave it nearly ready to go
- The virtual machine image is stored and ready to be used
The tool integrates naturally into CI/CD pipelines and infrastructure-as-code workflows, forming the foundation of what is known as a golden image. When combined with version control systems, you can treat machine images as versioned artefacts, tracking changes over time and maintaining audit trails of what's deployed in production.
Top Tip: never build golden images in the production network. Always have a dedicated network completely isolated from your other networks. You don’t want these builds to interfere with other workloads.
Configuration Phase
These golden images are seldom suitable to run in production without minor changes. For example, you may need to update IP addresses, rotate passwords, register instances in service discovery, or restart specific services before the system is ready to handle live traffic.
The configuration phase brings its own challenges. You need to write a script or an Ansible playbook to perform these final modifications and, more often than not, you also need a source of truth: a settings repository that contains the missing information required to complete the configuration, such as database passwords, API keys, or feature flags.
If you are running on hyperscalers you can employ their respective managed secrets services: AWS Secrets Manager or AWS Systems Manager Parameter Store on AWS; Azure Key Vault on Azure; and Google Secret Manager on Google Cloud. These services give you a centralised, auditable, and access-controlled location to store sensitive configuration data.
If you are running on-premises or in another cloud (and European clouds are nowadays attractive options in the current politically charged environment), consider a dedicated secrets manager such as OpenBao or HashiCorp Vault. These tools provide a consistent way to handle secrets, encryption keys, SSL certificates and dynamic credentials across heterogeneous environments, which is particularly valuable when your immutable images must be configured securely at first boot.
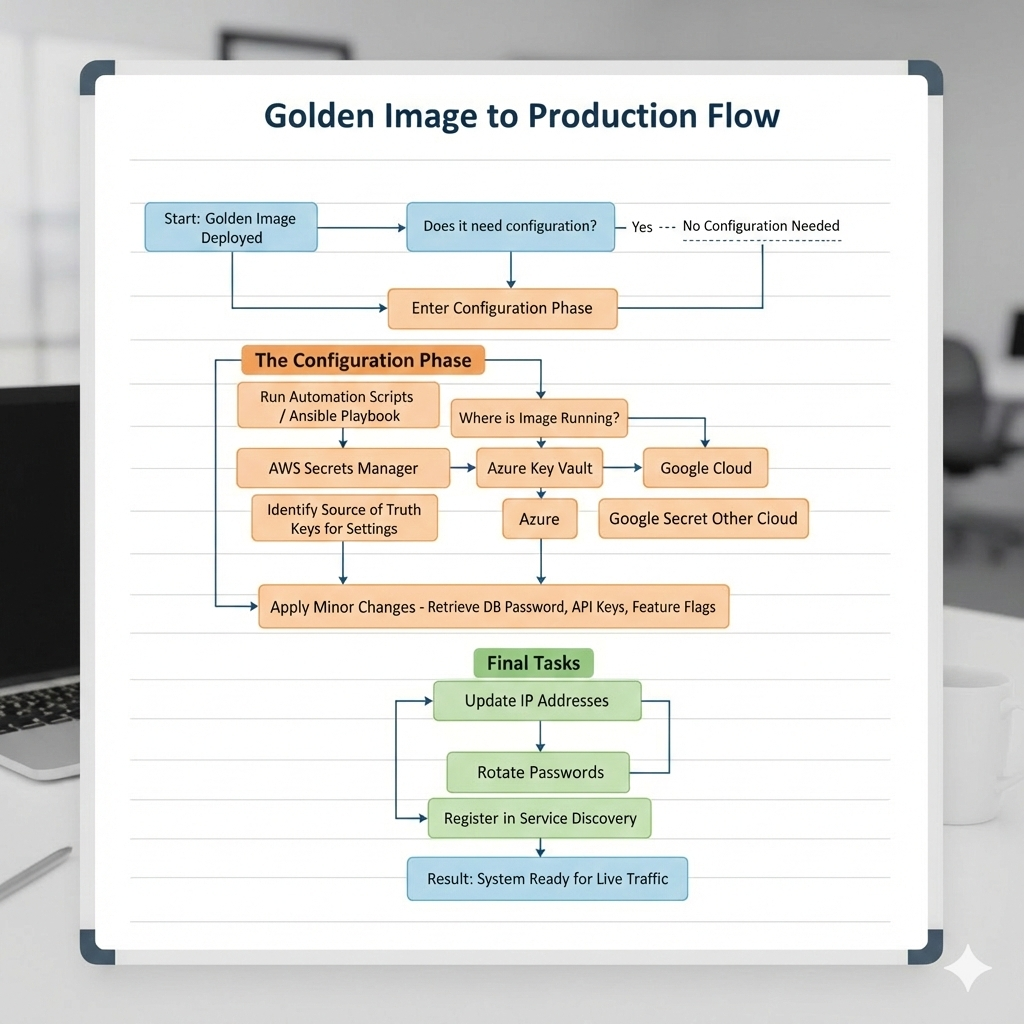
Some important lessons for this phase:
- It must be fast: you want your new server to be ready to go in seconds, not minutes
- Implement strong health checks: you must be able to determine quickly and efficiently whether all the services are up and running and healthy. This will determine whether the VM needs to be replaced or not.
- No drift: whatever method you use to complete the configuration, it must not introduce drifting: the resulting image should be the same no matter how many times you deploy it
Cattle, not pets
In many ways, these immutable images are treated as cattle similar to the concept embraced by Kubernetes where pods are not reusable, they’re just replaced, not reused. Because we have all the monitoring backed in and we’re able to see logs and metrics on centralised systems, we don’t even have the need to log in to these virtual machines and those requiring an extra level of security they often have SSH disabled or blocked by the firewall.
What happens if a VM fails? Destroy it and let your autoscaling group or CI/CD replace it.
Monitoring is reporting errors. Check the centralised logging system to determine the cause. If it’s not a transient error, destroy it and let your autoscaling group or CI/CD replace it.
Closing Thoughts
Immutable servers work best when this mindset is applied consistently, from image creation all the way through to incident response. That means resisting the temptation to "just SSH in and fix it" and instead treating every failure as a trigger to rebuild or replace from a known-good image. Over time, this changes the operational posture from reactive firefighting on snowflake servers to a calmer, more deterministic process where fixes are made in code, baked into images, and rolled out predictably across the fleet.
It also forces better engineering habits. Configuration drift becomes a signal that something in the pipeline is wrong, not an acceptable side effect of day-to-day operations. Debugging shifts towards improving observability, tightening health checks, and refining autoscaling or rollout strategies, rather than memorising bespoke runbooks for each box. In other words, the less you care about any individual VM, the more reliable the whole platform becomes.
At Digitalis, we've taken these principles beyond client implementations and applied them to building production-ready AMIs available on the AWS Marketplace. These images embody the same immutable infrastructure patterns we've refined through years of consultancy work: hardened base configurations, baked-in monitoring and observability tooling, and first-boot initialisation patterns that balance immutability with environment-specific flexibility. Whether you're bootstrapping a new project or standardising existing infrastructure, having battle-tested golden images as a starting point accelerates delivery whilst maintaining the security and reliability guarantees that immutable infrastructure promises.
For teams adopting this approach, the final step is cultural: make immutability the default, not the exception. Ensure playbooks, on-call procedures, and change management all assume that servers are disposable and reproducible. When that mindset lands, "cattle, not pets" stops being a slogan and becomes an operational advantage that directly improves uptime, security, and engineering velocity.
I for one welcome our new robot overlords


.png)