

Introduction
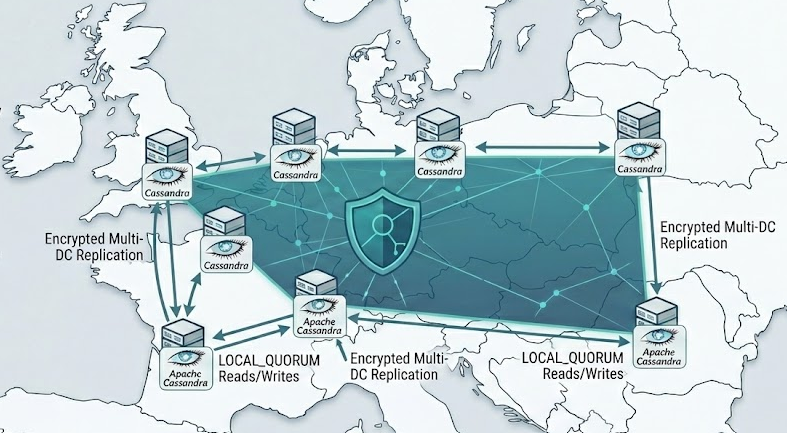
Spreading workloads across multiple European data centres is a direct expression of the Sovereign Stack model described in Europe's Sovereign Stack: A New Model for Innovation and Autonomy As Europe aligns a unified legal fabric (EU‑Inc), open source infrastructure, and strict data sovereignty, it becomes cheaper and safer to scale regionally than to centralise everything in a single US‑centric cloud region. Multi‑DC topologies let you keep data resident within EU jurisdictions, match data flows to local regulatory expectations, and avoid being a “tenant” of a single hyperscaler’s commercial or geopolitical risk. In other words, putting Cassandra across several European DCs is not just a resilience pattern; it is a compliance and autonomy pattern that turns GDPR and sovereignty from a constraint into a competitive moat.
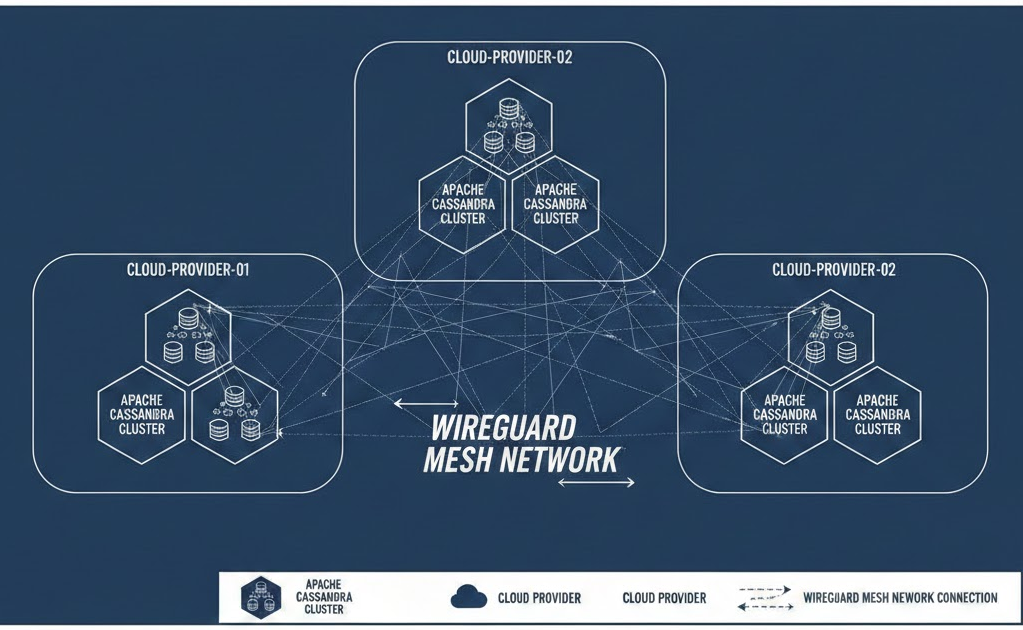
Apache Cassandra is a great example of software designed with linear scalability in mind not pinned to a single cloud or region. By overlaying a WireGuard-based-based mesh across heterogeneous providers and on‑prem sites, you can run a single Cassandra cluster spanning two or more data centres with encrypted, deterministic routing and failover paths.
From an engineering and business perspective, this makes a multi‑DC Cassandra deployment across European sites the logical default. An open source database, running over an open, provider‑agnostic WireGuard-based mesh, fits the Sovereign Stack’s aim of killing vendor lock‑in while keeping infrastructure auditable and transparent. You gain the ability to place DCs close to users in major hubs (EU, USA, Asia, etc), maintain LOCAL_QUORUM semantics inside each jurisdiction, and still replicate data under your control rather than via opaque, cross‑border managed services. Cassandra over WireGuard-based is the technical backbone that lets organisations grow their business while insulating themselves from political instability and staying clear of vendor lock‑in.
Why pair Cassandra with a WireGuard-based mesh?
Pairing Cassandra with a WireGuard-based mesh creates a cloud-agnostic overlay that decouples cluster topology from provider networks, providing uniform encryption and consistent addressing across clouds and on-premises environments. By using modern cryptography with a minimal control plane, it delivers deterministic, low-overhead security that is simpler than legacy IPSec or DMVPN approaches, while still supporting easy key rotation and straightforward peer bootstrapping. At the same time, any-node-to-any-node encrypted tunnels enable multi-pathing, so traffic can transparently shift to alternate routes during provider or transit failures, strengthening overall resilience.
Operationally, this model focuses on simplicity and automation. Declarative peer inventories integrate cleanly with tools such as Ansible and Terraform, keeping configuration repeatable and auditable as the mesh scales out. A predictable, usually UDP-based port model helps the overlay coexist with existing firewall policies and enterprise change controls, reducing friction for network and security teams. The combination of straightforward operations, clear routing behavior, and robust encryption makes WireGuard-based a strong fit for multi-DC Cassandra deployments that need both resilience and maintainability.
You can find a more hands-on lab on Mesh networks with headscale and tailscale in a previous blog.
Cassandra configuration for WAN-aware operation
Snitching and topology
Use GossipingPropertyFileSnitch with distinct DC and rack names for each physical site, keeping racks symmetrical to distribute replicas and repair load evenly. Set endpoint_snitch to GossipingPropertyFileSnitch (GPFS)and configure the dc and rack values in cassandra-rackdc.properties to match your actual physical layout so that topology-aware replication and failure domains behave as intended.
Ports, encryption, and authentication
For inter-node communication, enable TLS on the storage port (7001) even when running over WireGuard-based; the overlay secures the transport path, while TLS secures the Cassandra service itself, giving you defense in depth and enabling least privilege firewalling. For client connectivity, enable TLS on the native_transport_port (9042) and enforce client authentication as required, preferring mutual TLS for cross-site application access so that both clients and servers are strongly identified and traffic is protected end-to-end.
Failure detection and time discipline
On high-latency or intermittent WAN links you want Cassandra to be conservative about declaring nodes dead, otherwise you end up with replicas flapping in and out of service and routing decisions that oscillate every time the network wobbles. That’s why tuning failure detection is critical in a cross-DC mesh: raising phi_convict_threshold in multi-DC deployments makes gossip less trigger‑happy, at the cost of slightly slower detection when a node really is gone. The sweet spot depends on your real‑world latency and jitter, so you should validate changes with targeted chaos experiments, as described in Understanding phi_convict_threshold in Apache Cassandra: A Deep Dive into Failure Detection before applying them cluster‑wide.
Time discipline is just as important because Cassandra assumes that nodes broadly agree on what “now” means. Lightweight transactions, hinted handoff and repair are all sensitive to clock skew; even a few hundred milliseconds of drift can show up as inconsistent read behaviour, odd tombstone lifetimes or repair gaps that are hard to debug. The practical answer is strict, monitored NTP or Chrony on every node, with alerting on offset and jitter rather than treating time sync as a “set and forget” task. The patterns in The Silent Killer: Why Clock Synchronization Can Make or Break Your Cassandra Cluster go into more operational detail, but the principle is simple: treat clocks as part of your consensus layer, not just an OS default, especially once your cluster stretches across WAN links.
WireGuard-based mesh blueprint
Addressing and routes
Only advertise the Cassandra subnets through the WireGuard-based mesh so that you minimise unnecessary east–west exposure and keep the overlay focused on database traffic. Where possible, keep AllowedIPs static because it simplifies reasoning about the mesh. If you are using gateways, summarise the prefixes for each DC so that route tables stay small and you avoid unnecessary WireGuard-based handshake churn as the environment grows.
MTU and performance
Set the WireGuard-based MTU explicitly rather than relying on defaults; in practice this often lands somewhere between 1380 and 1420 bytes, depending on the underlay network and any intermediate encapsulation. Validate the chosen MTU with path MTU discovery and packet captures, especially during repairs and streaming, so you can confirm that large payloads are not being fragmented or silently dropped and that the overlay behaves predictably under load.
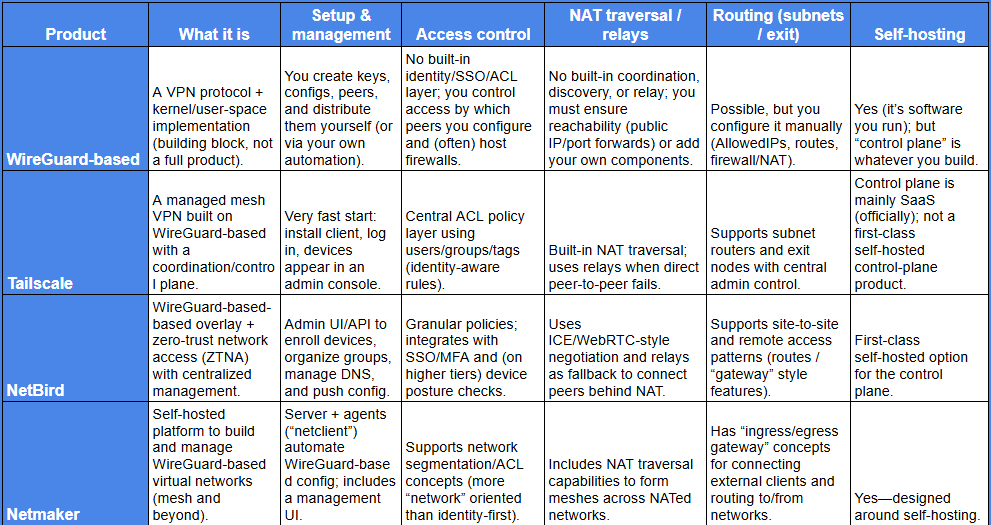
Below is a simpler, “main features” comparison of plain WireGuard-based vs Tailscale vs NetBird vs Netmaker, focusing on what you get out of the box.
Data modelling and consistency across DCs
In multi–data centre deployments, Cassandra is designed for LOCAL_QUORUM within a DC rather than synchronous coordination across regions. You should design replication and consistency so that normal reads and writes stay inside the local DC, and reserve cross‑DC traffic for replication, repair, and the rare query that genuinely needs a global view. In practice this means using NetworkTopologyStrategy keyspaces with a per‑DC replication factor (RF) of 3, and keeping RF symmetric between DCs so that failure behaviour and runbooks are the same everywhere. Set the application’s default consistency level to LOCAL_QUORUM for both reads and writes so that a majority of replicas in the local DC must respond, which gives you predictable latency and “latest write in this DC” semantics without WAN hops. Treat EACH_QUORUM (writes only) as an exceptional option for workloads that really need a quorum in every DC, and test it carefully under node and DC‑level failure because it adds cross‑DC latency and can reduce write availability. Plan repairs per DC as well, running repairs often enough that each DC completes within its own maintenance window and staggering those windows between sites so repairs and streaming don’t contend for WAN.
If you are using AxonOps for operations and monitoring, just enable Adaptive Repairs.
Equally important is configuring clients so that the coordinator node is in the same DC as the application whenever possible. Drivers should be DC‑ and rack‑aware so that applications talk to the nearest Cassandra DC by default, and only fall back to other DCs when the local one is degraded. For Java applications, this typically means using a DC‑aware, token‑aware load‑balancing policy (for example TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().withLocalDc("myDC").build())) and setting localDc to the Cassandra DC closest to the application. With this in place, LOCAL_QUORUM truly means “quorum of replicas in the same DC as the coordinator,” so read latencies remain stable and cross‑DC hops are mostly limited to background replication, planned failover, and disaster‑recovery workflows instead of becoming an accidental default.
Other considerations
Seeds: Use a per‑DC seed selection, but keep the same seed list on every node in the entire cluster. That cluster-wide list should include at least two seed nodes from each DC, chosen from different racks / failure domains. Avoid configuring nodes to rely on seeds that exist only in a remote DC (for example, a node in DC1 should not have seeds exclusively in DC2), and don’t vary the seed list between nodes.
Example: In a 3‑DC cluster, configure a single seed list that contains 22 nodes from DC1, 22 from DC2, and 22 from DC3 (spread across racks), and apply that identical list to all nodes.
TLS: Enable both node‑to‑node and client‑to‑node TLS regardless of any underlying VPN or WireGuard-based tunnels, and use short‑lived certificates with automated renewal and rotation. Consider using OpenBao or HashiCorp Vault to manage the certificates creation.
Observability: Monitor tunnel latency and packet loss, Cassandra latency percentiles, repair progress/backlog, hinted handoff volume, and clock skew between nodes. Use a monitoring platform such as AxonOps to collect these metrics, build DC‑aware dashboards, and correlate alerts so WAN brownouts don’t cause noisy, low‑value paging. You can do all of this and more with AxonOps.
Closing Thoughts
For platform teams, a multi-DC Cassandra footprint over a WireGuard-based mesh advances the Sovereign Stack on four fronts: sovereignty (data locality per jurisdiction), resilience (any-node encrypted paths and LOCAL_QUORUM by DC), cloud-agnosticism (provider-neutral overlay), and operational simplicity (small crypto surface, declarative peer inventories). Digitalis.IO brings the battle-tested patterns to design, harden, and automate these topologies, while AxonOps closes the loop with DC-aware observability, adaptive repairs, and safe day-2 operations. If you are evolving toward an EU-first, standards-led platform, this blueprint lets you scale across providers without inheriting their risks, keeping control, compliance, and performance firmly in your hands.
I, for one, welcome our new robot overlords


